Zero-shot Video Classification
TLDR: Our research focuses on the implicit and explicit diversification of semantics. In our work presented at CVPR2022, we introduce alignment-uniformity representation learning (AURL), which encourages semantic features to preserve maximal information on a unit hypersphere, thereby implicitly diversifying the semantics. Additionally, we have submitted our recent research VAPNet on explicit semantic diversification to ICCV 2023. In this work, we propose a novel concept called “video attributes,” which leverages video captions to fuse existing class descriptions. This approach enables each semantic attribute to adapt to corresponding videos, enhancing the diversity and adaptability of the semantics.
Alignment-Uniformity Representation Learning for Zero-shot Video Classification (AURL)

Research: Existing methods primarily focus on aligning video features with text features but struggle to establish an end-to-end visual-text feature learning approach due to the challenge of model collapse caused by the joint learning of low-level visual and high-level text features. In contrast, our AURL approach introduce a supervised contrastive loss to achieves successful joint learning of visual-semantic features and effectively mitigates model collapse. The supervised contrastive loss not only ensures alignment but also guarantees uniformity (or diversity) in the learned multimodal representation.

The uniformity property of our approach encourages features to spread uniformly on the unit hypersphere. To assess the alignment and uniformity of the learned representations, we introduce two new metrics: closeness and dispersion. Closeness measures the average distance between features within the same class, while dispersion measures the minimum distances among all clusters. We can see that before versus after the introduced losses, the representations within the same class become tighter, while the differentiation between classes becomes more evident. This is particularly important for zero-shot learning, because a more coherent and distinct representation space will facilitate better generalization for unseen classes. Please see the full paper at CVPR’23, slides and code
Application: Tencent promotes the implementation of AURL in real business scenarios on their platform to the masses (in Chinese). They mentioned that the preliminary model of AURL has been applied in Tencent Advertising, WeChat Search, and WeChat Video Account Recommendation, resulting in significant improvements in business metrics.
Video Attribute Prototype Network: A New Perspective for Zero-Shot Video Classification (VAPNet)

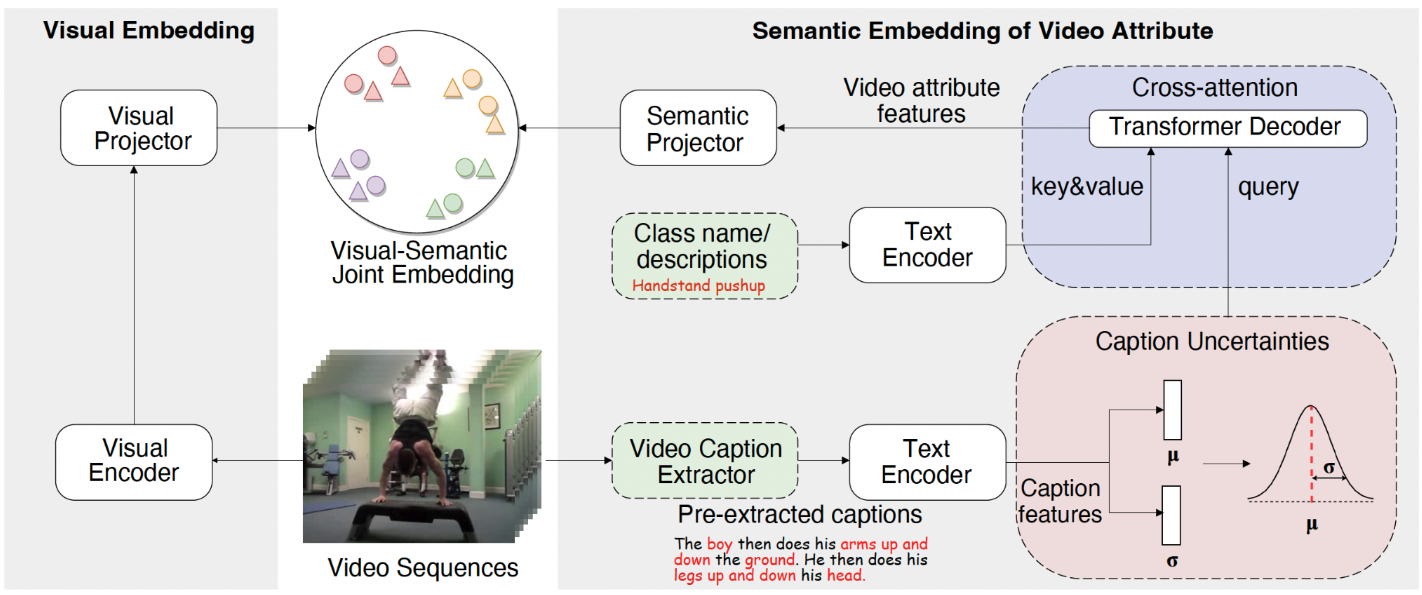
In contrast to the concept of “image attributes” that describes the properties of individual images, our paper introduces a novel concept called “video attributes” to describe video content using video captions and class name descriptions (above fig). To effectively combine video captions and class name descriptions, we propose a cross-attention module. This module encourages the model to focus on relevant parts of the captions and align them with the features of the class names, which enables the model to handle the variability and complexity present in video data. Besides we propose an uncertainty module to address the challenge of inherent noise in video captions by encoding uncertainty in the variance of a Gaussian distribution while utilizing its mean for representation.