
Facial Action Unit Analysis
TLDR: Our research addresses three key challenges in facial Action Unit (AU) analysis: (1) limited availability of AU annotations, (2) label correlation, and (3) incorporating structured features of face regions. To tackle these challenges, we propose a weakly supervised learning approach that leverages one million web images with weak annotations (query keywords) to enhance existing AU classifiers. Additionally, we introduce a joint region learning and multi-label learning mechanism that serves as a benchmark in the field of facial AU analysis. These series of work are supported by NSF of China, NIH, and the prelimary model is deployed in depression detection of Beijing Anding Hospital.
Learning Facial Action Units from Web Images with Scalable Weakly Supervised Clustering (WSC)

We present a scalable weakly supervised clustering approach to learn facial action units (AUs) from large, freely available web images. Unlike most existing methods (eg, CNNs) that rely on fully annotated data, our method exploits web images with inaccurate annotations. Specifically, we derive a weakly-supervised spectral algorithm that learns an embedding space to couple image appearance and semantics. The algorithm has efficient gradient update, and scales up to large quantities of images with a stochastic extension. With the learned embedding space, we adopt rank-order clustering to identify groups of visually and semantically similar images, and re-annotate these groups for training AU classifiers. Evaluation on the 1 millon EmotioNet dataset demonstrates the effectiveness of our approach:(1) our learned annotations reach on average 91.3% agreement with human annotations on 7 common AUs,(2) classifiers trained with re-annotated images perform comparably to, sometimes even better than, its supervised CNN-based counterpart, and (3) our method offers intuitive outlier/noise pruning instead of forcing one annotation to every image. Please see CVPR18, code.
Deep Region and Multi-label Learning for Facial Action Unit Detection (DRML)

Region learning (RL) and multi-label learning (ML) have recently attracted increasing attentions in the field of facial Action Unit (AU) detection. Knowing that AUs are active on sparse facial regions, RL aims to identify these regions for a better specificity. On the other hand, a strong statistical evidence of AU correlations suggests that ML is a natural way to model the detection task. In this paper, we propose Deep Region and Multi-label Learning (DRML), a unified deep network that simultaneously addresses these two problems. One crucial aspect in DRML is a novel region layer that uses feed-forward functions to induce important facial regions, forcing the learned weights to capture structural information of the face. Our region layer serves as an alternative design between locally connected layers (i.e., confined kernels to individual pixels) and conventional convolution layers (i.e., shared kernels across an entire image). Unlike previous studies that solve RL and ML alternately, DRML by construction addresses both problems, allowing the two seemingly irrelevant problems to interact more directly. The complete network is end-to-end trainable, and automatically learns representations robust to variations inherent within a local region. Experiments on BP4D and DISFA benchmarks show that DRML performs the highest average F1-score and AUC within and across datasets in comparison with alternative methods. Please check CVPR16, code.
Joint Patch and Multi-label Learning for Facial Action Unit Detection (JPML)
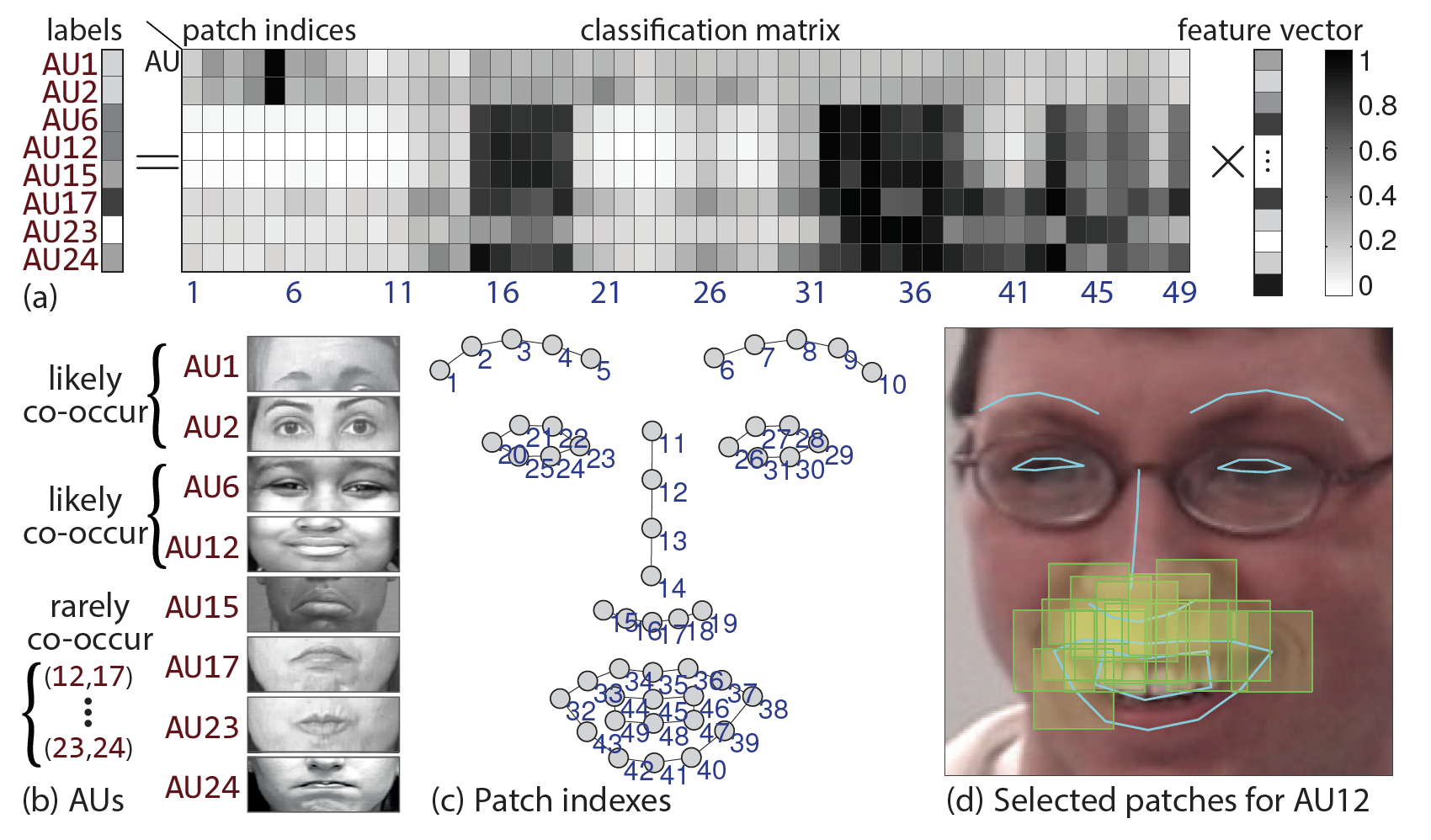
Most action unit (AU) detection methods use one-vs-all classifiers without considering dependencies between features or AUs. In this paper, we introduce a Joint Patch and Multi-label Learning (JPML) framework that models the structured joint dependency behind features, AUs, and their interplay. In this paper, we introduce a Joint Patch and Multi-label Learning (JPML) framework that models the structured joint dependency behind features, AUs, and their interplay. Specifically, JPML leverages group sparsity to identify important facial patches, and learns a multi-label classifier constrained by the likelihood of co-occurring AUs. To describe such likelihood, we derive two AU relations, positive correlation and negative competition, by statistically analyzing more than 350,000 video frames annotated with multiple AUs. To the best of our knowledge, this is the first work that jointly addresses patch learning and multi-label learning for AU detection. In addition, we show that JPML can be extended to recognize holistic expressions by learning common and specific patches, which afford a more compact representation than standard expression recognition methods. We evaluate JPML on three benchmark datasets CK plus, BP4D and GFT, using within- and cross-dataset scenarios. In four of five experiments, JPML achieved the highest averaged F1 scores in comparison with baseline and alternative methods with either patch learning or multi-label learning alone. Please check CVPR15, code, TIP16.